マルチモーダルCoTプロンプティング
Zhang et al. (2023) (opens in a new tab)は、最近、マルチモーダルの思考連鎖プロンプティングアプローチを提案しました。従来のCoTは言語モダリティに焦点を当てています。対照的に、マルチモーダルCoTは、テキストとビジョンを2段階のフレームワークに組み込んでいます。最初のステップは、マルチモーダル情報に基づく理由生成です。これに続いて、情報量の多い生成された理由を活用した回答推論が行われます。
マルチモーダルCoTモデル(1B)は、ScienceQAベンチマークでGPT-3.5を上回る性能を発揮しています。
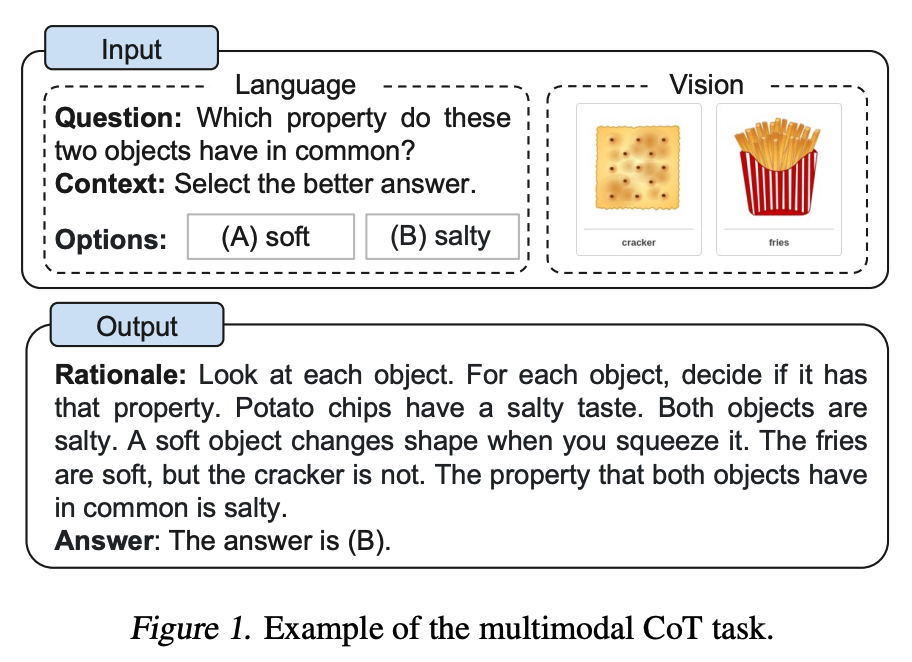
Image Source: Zhang et al. (2023) (opens in a new tab)
詳細は以下を参照してください: